Hannes Heikinheimo
Sep 19, 2023
1 min read
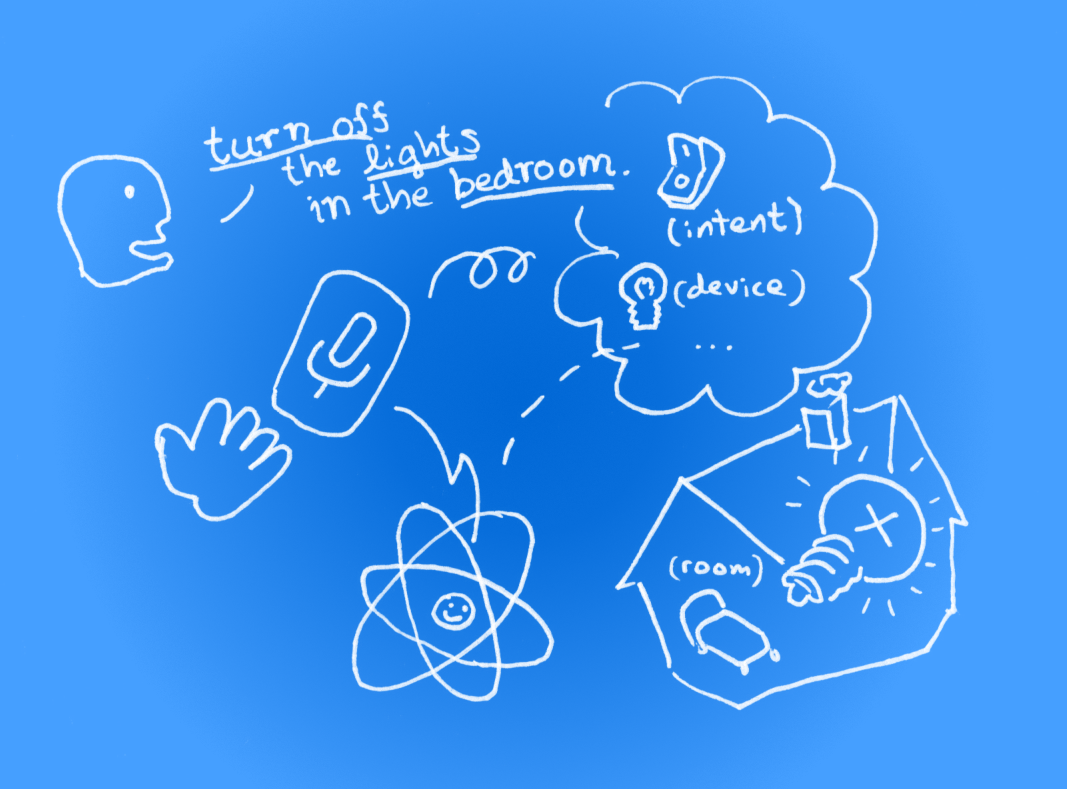
To demonstrate writing voice-enabled apps in practice, we’ll build a smart home controller app that responds with real-time visual feedback to spoken commands like:
"Switch off the radio in the living room."
"Turn on the lights in the bedroom."
The app is going to be built on two design pillars in particular:
Responsiveness, so that the user is confident that the app follows the user’s speech.
Robustness, so that app behaves nicely even if the interpretation of the user’s intents changes during the sentence.
By definition, speech-to-text systems give you text (transcript) to work with. Real-time systems provide partial sentences as soon as words are recognised and continue to refine the transcript as the speech progresses.
In addition to this, Speechly, for one, goes a step further by providing you with tagged keywords (entities) and the intent of the sentence as soon as they are recognised. At first, they would be tagged as tentative, and later turn to final.
The above example sentences would be deconstructed as follows:
"Switch off the radio in the living room"
_→ _Intent: turn_off, entities: radio (of type device), living room (of type room)
The tags are defined in a voice interface configuration in Speechly Annotation Language (SAL). While I’ve pre-configured the keywords for this example, you can learn how to create your own voice interfaces here.
While we're getting a constant stream of words as the sentence is being uttered, the speaker’s true intentions are only confirmed at the end of sentence (which Speechly calls a final segment).
Let’s assume the user would say "Turn the kitchen lights... on".
If we would wait until the end of the sentence before providing any feedback to the user, the time from manipulation (speech) to desired effect may increase to several seconds, rendering the user experience unresponsive and clumsy.
To mitigate this, we will highlight the objects mentioned in the sentence (appliances like "lights" and rooms) to give the user an early confirmation of where and what changes would happen. The speaker may even use this near real-time information to alter his spoken command.
If we wanted, we could even take a more forward leaning approach by actually toggling the lights when we have enough information about the user's intent.
To deliver the robust experience users expect, we need to be prepared for the (luckily, rare) occasion that the intent changes as the speech progresses, sometimes at the very last moment. What if the user would have finished the above sentence with an "...off"?
We'll facilitate the changes (big or small) by storing a copy of the app state when the user starts a new sentence. Then we simply recalculate the new state over and over again using the information we receive as the user speaks. By operating on the whole app state allows speech to control all aspects of the application: adding, removing and modifying data on any number of objects are all handled in a similar manner. Reflecting the information upon the last stable state becomes especially important should the interpretation of the user’s intent change in the middle of the sentence. Finally we store the last tentative state as the new stable state for upcoming sentences.
This approach assumes that your app state is fairly compact so that you can effectively create a new copy of the entire app state upon new information becomes available from the speech to text engine, which may occur up to 10 times a second. Also, the user interface needs to be fast enough to keep up with state updates so that won't choke the performance.
Let's create a sample app to see how it all comes together.
I'm assuming that you have some experience with React so you probably already have node/npm installed. If you want run the demo, prepare a React TypeScript project, but with contents of src/App.tsx replaced with this Gist like so:
npx create-react-app home-automation --template typescript
cd home-automation
# Download and replace src/App.tsx with the Home Automation app
curl https://gist.githubusercontent.com/arzga/da22da22782e0b79c2271ed0f206d6df/raw > src/App.tsx
# Install dependencies
npm install
npm install @speechly/react-client @speechly/react-ui
npm start
Before walking thru the code, a word about some of the choices I’ve made:
The main render function is probably pretty much what you’d expect it to be in a React app. The whole of the app is wrapped in a <SpeechProvider> which connects to the Speechly cloud services and enables speech-to-text for any contained component. The appId points to a pre-configured voice interface that defines the keywords and phrases you can use in this app.
export default function App() {
return (
<div className="App">
<SpeechProvider
appId="a14e42a3-917e-4a57-81f7-7433ec71abad"
language="en-US"
>
<BigTranscriptContainer>
<BigTranscript />
</BigTranscriptContainer>
<SpeechlyApp />
<PushToTalkButtonContainer>
<PushToTalkButton captureKey=" " />
</PushToTalkButtonContainer>
</SpeechProvider>
</div>
);
}
The app has a monolithic state object (think of a React/Redux store). The data model is just a collection of rooms with device states in them. It’s worth noting that the names match those of the entities defined in the voice interface configuration mentioned above. This way the entities returned by the speech-to-text API are easy to connect with the model.
const DefaultAppState = {
rooms: {
'living room': {
radio: false,
television: false,
lights: false,
},
bedroom: {
radio: false,
lights: false,
},
kitchen: {
radio: false,
lights: false,
},
},
};
The details of the state manipulation logic reside in alterAppState, which takes the segment and last “stable” appstate and returns a new app state object with segment information reflected on it.
selectedRoom and selectedDevice are used to highlight the objects the user talks in the user interface.
const alterAppState = useCallback(
(segment: SpeechSegment): AppState => {
switch (segment.intent.intent) {
case 'turn_on':
case 'turn_off':
// Get values for room and device entities.
const room = segment.entities
.find((entity) => entity.type === 'room')
?.value.toLowerCase();
const device = segment.entities
.find((entity) => entity.type === 'device')
?.value.toLowerCase();
setSelectedRoom(room);
setSelectedDevice(device);
// Set desired device powerOn based on the intent
const isPowerOn = segment.intent.intent === 'turn_on';
if (
room &&
device &&
appState.rooms[room] !== undefined &&
appState.rooms[room][device] !== undefined
) {
return {
...appState,
rooms: {
...appState.rooms,
[room]: { ...appState.rooms[room], [device]: isPowerOn },
},
};
}
break;
}
return appState;
},
[appState],
);
As the user speaks, the useEffect below fires as a response to changed words, entities and intent in segment. The new tentativeAppState is then resolved by calling alterAppState. Upon the end of the sentence (indicated by the segment.isFinal flag) the last tentativeAppState is stored as the new “stable” appState.
function SpeechlyApp() {
const { segment } = useSpeechContext();
const [tentativeAppState, setTentativeAppState] = useState<AppState>(DefaultAppState);
const [appState, setAppState] = useState<AppState>(DefaultAppState);
const [selectedRoom, setSelectedRoom] = useState<string | undefined>();
const [selectedDevice, setSelectedDevice] = useState<string | undefined>();
// This effect is fired whenever there's a new speech segment available
useEffect(() => {
if (segment) {
let alteredState = alterAppState(segment);
// Set current app state
setTentativeAppState(alteredState);
if (segment.isFinal) {
// Store the final app state as basis of next utterance
setAppState(alteredState);
setSelectedRoom(undefined);
setSelectedDevice(undefined);
}
}
// eslint-disable-next-line react-hooks/exhaustive-deps
}, [segment]);
...
The remaining part is rendering the rooms as boxes with devices in them. The renderer uses the information both in the appState and tentativeState to highlight changes to the device states. The selected room and devices are also visualised during the utterance.
return (
<div
style={{
display: "flex",
height: "100vh",
flexDirection: "row",
justifyContent: "center",
alignItems: "center",
alignContent: "center",
flexWrap: "wrap",
}}
>
{Object.keys(appState.rooms).map((room) => (
<div
key={room}
style={{
width: "12rem",
height: "12rem",
padding: "0.5rem",
borderWidth: "2px",
borderStyle: "solid",
borderColor: selectedRoom === room ? "cyan" : "black",
}}
>
{room}
<div
style={{
paddingTop: "1rem",
display: "flex",
flexDirection: "row",
justifyContent: "start",
alignItems: "start",
flexWrap: "wrap",
}}
>
{Object.keys(appState.rooms[room]).map((device) => (
<div
key={device}
style={{
flexBasis: "5rem",
margin: "0.2rem",
padding: "0.2rem",
background:
selectedDevice === device &&
(!selectedRoom || selectedRoom === room)
? "cyan"
: "lightgray",
}}
>
{device}
<br />
{appState.rooms[room][device] ? (
tentativeAppState.rooms[room][device] ? (
<span style={{ color: "green" }}>On</span>
) : (
<span style={{ color: "red" }}>Turning off...</span>
)
) : !tentativeAppState.rooms[room][device] ? (
<span style={{ color: "red" }}>Off</span>
) : (
<span style={{ color: "green" }}>Turning on...</span>
)}
</div>
))}
</div>
</div>
))}
</div>
);
}
That’s it!
If you created the React app and downloaded the Gist, you should be able to run it, hold the mic button (or hold down the space bar) and try saying combinations of ”turn on”, ”turn off”, ”lights”, ”radio”, ”television” and rooms like ”living room”, ”bedroom” and ”kitchen”.
Hopefully you now have an idea how you can integrate a voice interface to your React app. The next step would be creating something of your own. A good starting point would be thinking of what kind of phrases you’d like to use and sketch them out in Speechly Dashboard.
Happy hacking!
Ari
Speechly is a YC backed company building tools for speech recognition and natural language understanding. Speechly offers flexible deployment options (cloud, on-premise, and on-device), super accurate custom models for any domain, privacy and scalability for hundreds of thousands of hours of audio.
Hannes Heikinheimo
Sep 19, 2023
1 min read
Voice chat has become an expected feature in virtual reality (VR) experiences. However, there are important factors to consider when picking the best solution to power your experience. This post will compare the pros and cons of the 4 leading VR voice chat solutions to help you make the best selection possible for your game or social experience.
Matt Durgavich
Jul 06, 2023
5 min read
Speechly has recently received SOC 2 Type II certification. This certification demonstrates Speechly's unwavering commitment to maintaining robust security controls and protecting client data.
Markus Lång
Jun 01, 2023
1 min read